Abstract
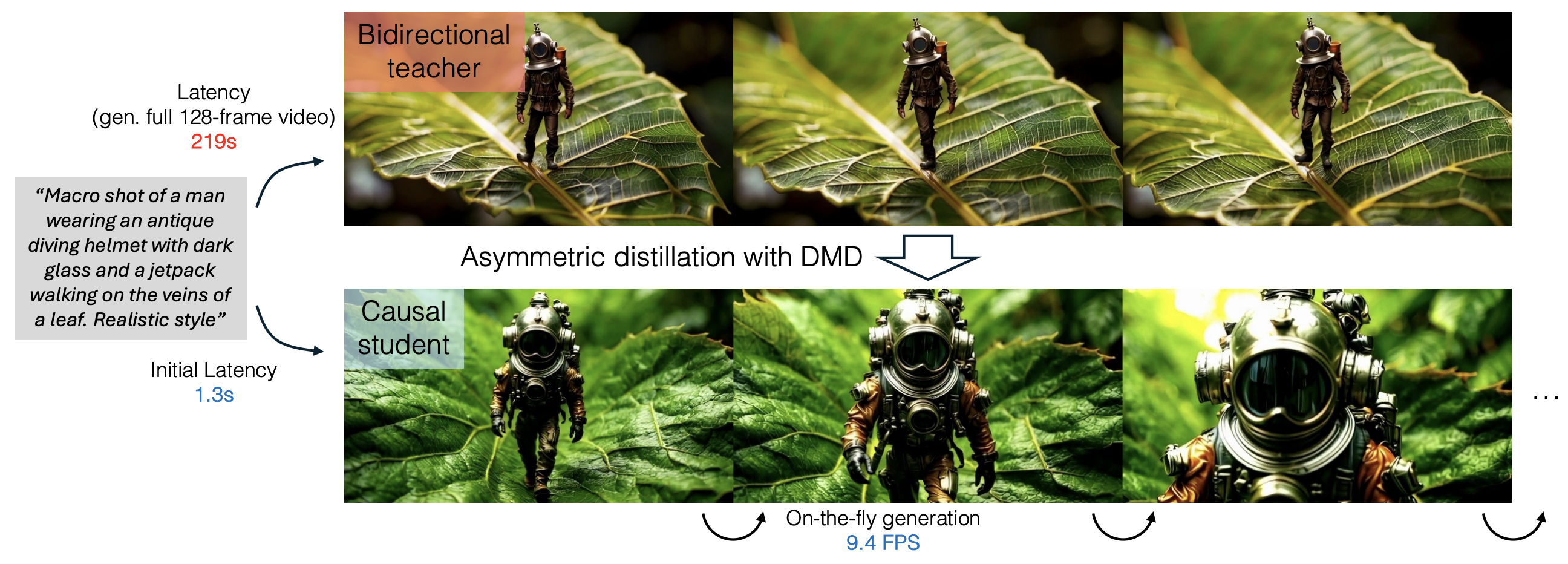
Current video diffusion models achieve impressive generation quality but struggle in interactive applications due to bidirectional attention dependencies. The generation of a single frame requires the model to process the entire sequence, including the future. We address this limitation by adapting a pretrained bidirectional diffusion transformer to an autoregressive transformer that generates frames on-the-fly. To further reduce latency, we extend distribution matching distillation (DMD) to videos, distilling 50-step diffusion model into a 4-step generator. To enable stable and high-quality distillation, we introduce a student initialization scheme based on teacher's ODE trajectories, as well as an asymmetric distillation strategy that supervises a causal student model with a bidirectional teacher. This approach effectively mitigates error accumulation in autoregressive generation, allowing long-duration video synthesis despite training on short clips. Our model achieves a total score of 84.27 on the VBench-Long benchmark, surpassing all previous video generation models. It enables fast streaming generation of high-quality videos at 9.4 FPS on a single GPU thanks to KV caching. Our approach also enables streaming video-to-video translation, image-to-video, and dynamic prompting in a zero-shot manner. We will release the code based on an open-source model in the future.
CausVid Method Overview
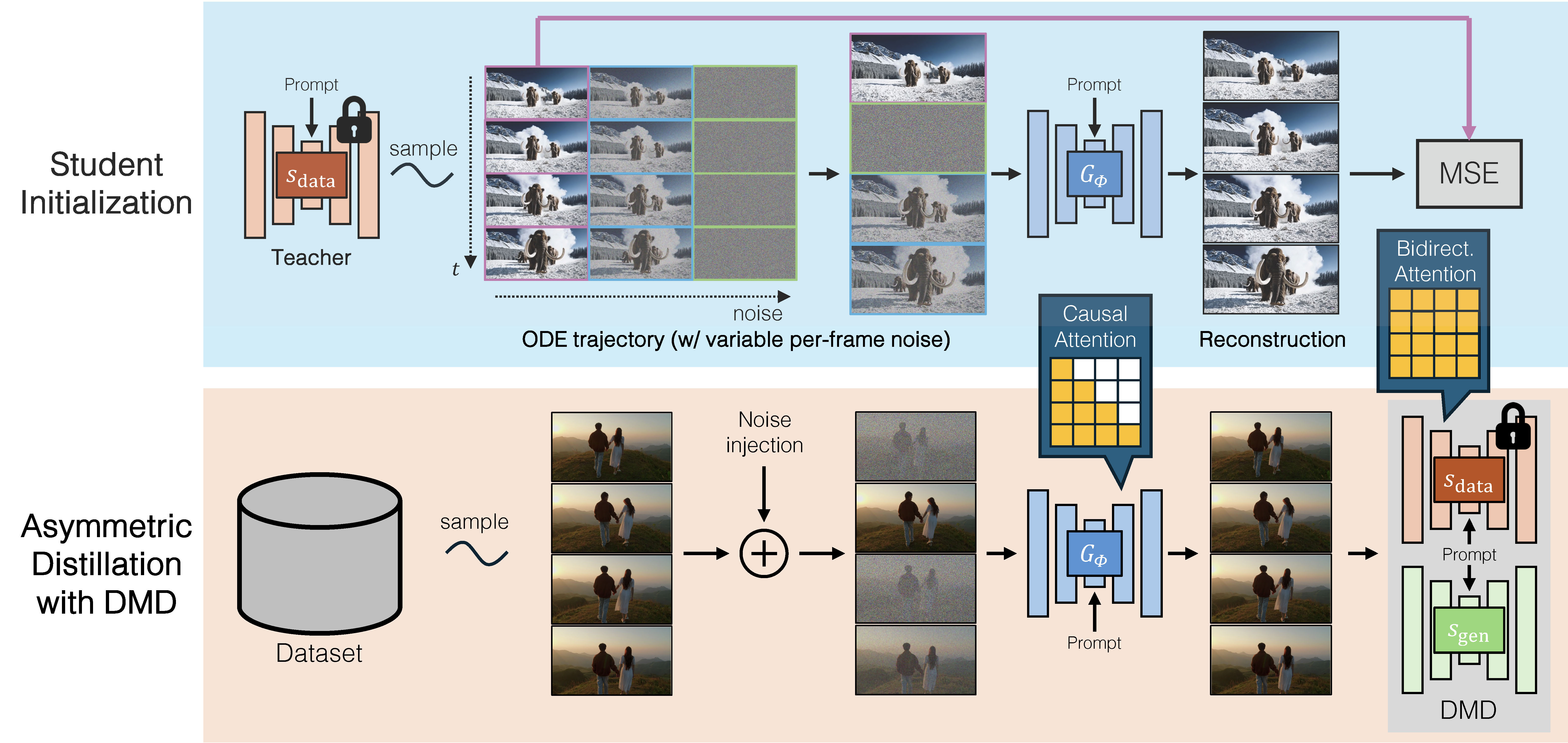
Our method distills a many-step, bidirectional video diffusion model sdata into a 4-step, causal generator Gϕ. The training process consists of two stages: (1) Student Initialization: We initialize the causal student by pretraining it on a small set of ODE solution pairs generated by the bidirectional teacher. This step helps stabilize the subsequent distillation training. (2) Asymmetric Distillation: Using the bidirectional teacher model, we train the causal student generator through a distribution matching distillation loss.
State-of-the-art Text-to-Video Generation Quality
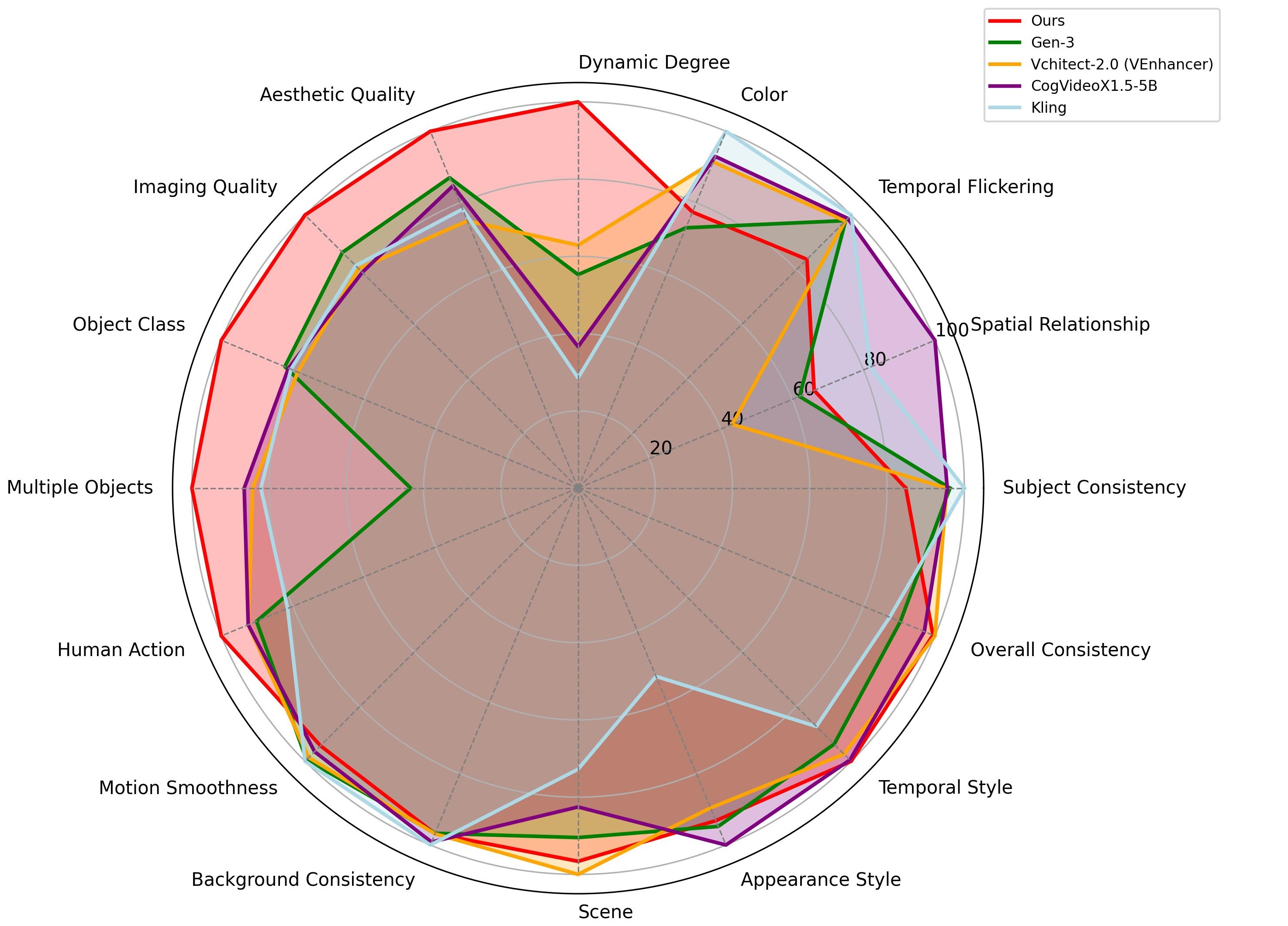
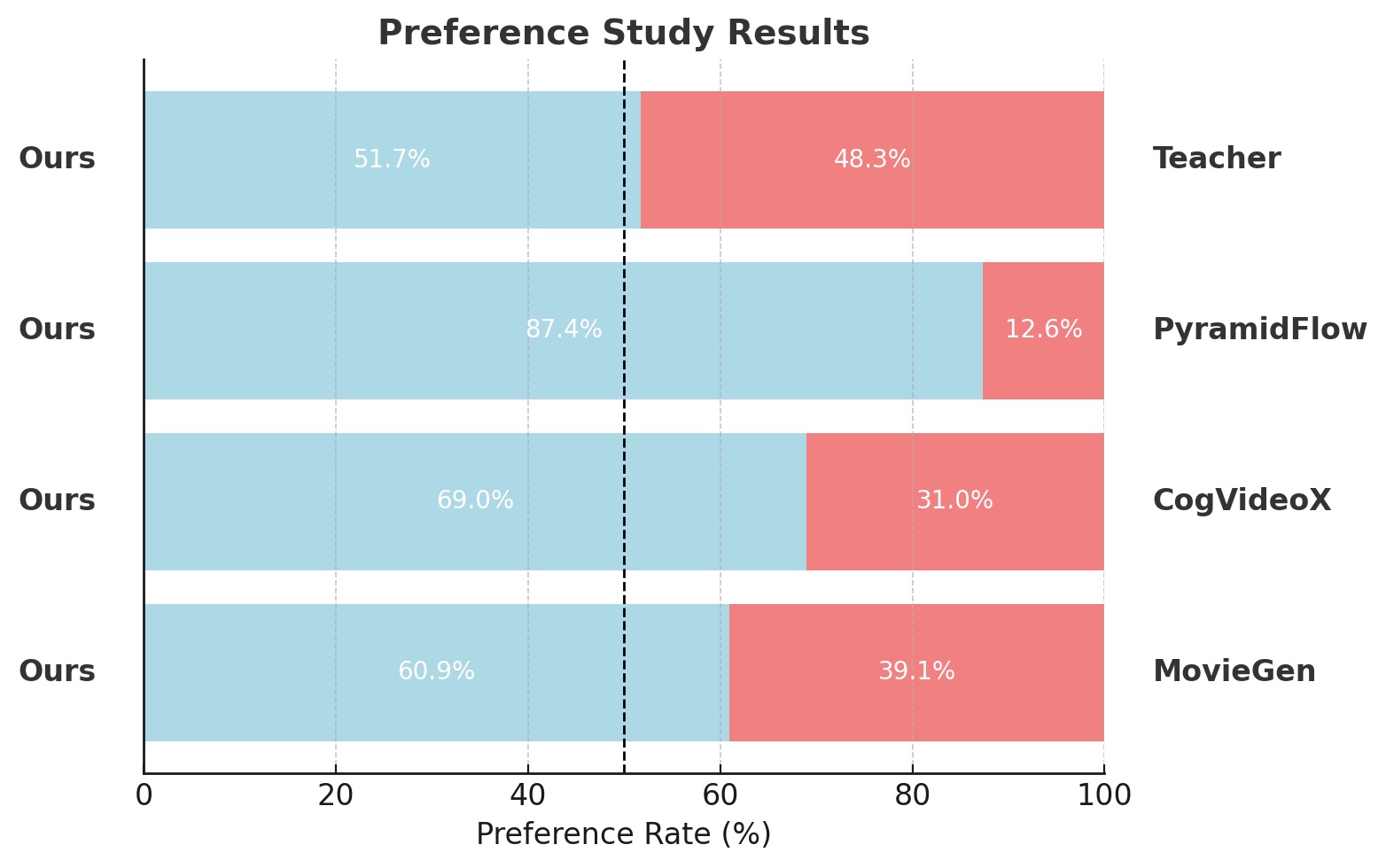
Our model achieves a total score of 84.27 on VBench (see VBench Leaderboard) ranking the first place among all verified submissions and uniquely enabling fast streaming inference on a single GPU at 9.4 FPS. The radar plot visualizes our method's comprehensive performance advantages across several key metrics, including dynamic degree, aesthetic quality, imaging quality, object class, multiple objects, and human action. Additionally, based on our human evaluation, our fast model surpasses competing approaches—such as CogVideoX, PyramidFlow, MovieGen, and our bidirectional teacher—all of which are significantly slower by several orders of magnitude.
Interactive UI
We present an interactive user interface (UI) featuring text-to-10s video generation, infinitely long video generation through sliding window inference, and image-to-video generation capabilities.
Text to 5-second Short Video Generation
Our model generates high-quality videos from text with an initial latency of just 1.3-second, after which frames are generated continuously in a streaming fashion at approximately 9.4 FPS on a single GPU. Our model supports generation at both 12 and 24 FPS. Below, we present 5-second video results (24 FPS) using prompts from MovieGenBench and a fixed random seed of 0.
A scene that is infinitely boring in its infinite complexity
The slow melting of a snowman, with water trickling down its sides and puddles forming around its base as the temperature warms.
A dynamic motion shot of a paper airplane morphing into a swan. The pointed nose becomes a graceful neck and head, wings unfolding and expanding. The camera moves around as the flat surfaces gain volume, creases softening into feathers. The tail section splits into webbed feet. The transformation finishes as the swan's plumage turns pristine white, its beak forming from the paper's final fold.
An imposing, atomic-powered, retro-futuristic robot strides down the red carpet at a glamorous movie premiere. Its bulky, gleaming exosuit shines under the bright lights of camera flashes, reflecting the glitz of the event. The robot’s large, round helmet, with its glowing visor, gives it an air of mysterious authority, while the articulated joints in its thick, metallic arms and legs move with precision. Its jetpack, attached to its back, hums softly as it powers the machine forward, and the crowd marvels at the fusion of vintage design and futuristic technology
A breathtaking image of a meteor colliding with the surface of a planet, with bright flames and a massive explosion, illustrating the power and destruction of such an event.
Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
Cinematic closeup and detailed portrait of a reindeer in a snowy forest at sunset. The lighting is cinematic and gorgeous and soft and sun-kissed, with golden backlight and dreamy bokeh and lens flares. The color grade is cinematic and magical.
a spooky haunted mansion, with friendly jack o lanterns and ghost characters welcoming trick or treaters to the entrance, tilt shift photography
An extreme close-up of an gray-haired man with a beard in his 60s, he is deep in thought pondering the history of the universe as he sits at a cafe in Paris, his eyes focus on people offscreen as they walk as he sits mostly motionless, he is dressed in a wool coat suit coat with a button-down shirt , he wears a brown beret and glasses and has a very professorial appearance, and the end he offers a subtle closed-mouth smile as if he found the answer to the mystery of life, the lighting is very cinematic with the golden light and the Parisian streets and city in the background, depth of field, cinematic 35mm film.
close up shot of a woman, police lights flashing in background, cinematic, low contrast
in a beautifully rendered papercraft world, a steamboat travels across a vast ocean with wispy clouds in the sky. vast grassy hills lie in the distant background, and some sealife is visible near the papercraft ocean's surface
Macro shot of a man wearing an antique diving helmet with dark glass and a jetpack walking on the veins of a leaf. Realistic style
A Samoyed and a Golden Retriever dog are playfully romping through a futuristic neon city at night. The neon lights emitted from the nearby buildings glistens off of their fur.
Carefully pouring the milk into the cup, the milk flowed smoothly and the cup was gradually filled with a milky white color
Text to 30-second Long Video Generation
While our generator is trained on short video clips, its autoregressive nature enables it to produce videos of infinite length using sliding window inference. Below, we present 30-second video results (24 FPS) generated with prompts from MovieGenBench and a fixed random seed of 0.
Miniature adorable monsters made out of wool and felt, dancing with each other, 3d render, octane, soft lighting, dreamy bokeh, cinematic.
Panda bear wearing gold-plated stiletto shoes strutting with a sassy demeanor through a haute couture runway
In a magical garden, plants change colors with each passing breeze, their leaves shimmering and fluttering as a person walks through, reaching out to touch the transforming flora.
Baby dragon
Camera tracking shot. A man walking down a city street, holding a coffee cup in his hand. He is wearing a dark suit and red tie.
A bear made of strawberrys is walking in the forest, its eyes looking around as if it is seeing the world for the first time.
3D animation of a small, round, fluffy creature with big, expressive eyes explores a vibrant, enchanted forest. The creature, a whimsical blend of a rabbit and a squirrel, has soft blue fur and a bushy, striped tail. It hops along a sparkling stream, its eyes wide with wonder. The forest is alive with magical elements: flowers that glow and change colors, trees with leaves in shades of purple and silver, and small floating lights that resemble fireflies. The creature stops to interact playfully with a group of tiny, fairy-like beings dancing around a mushroom ring. The creature looks up in awe at a large, glowing tree that seems to be the heart of the forest.
The gentle bubbling and evaporation of water in a natural hot spring, with mist rising and drifting across the surrounding landscape.
Visual: A night scene in a city with wet streets reflecting city lights. The camera starts on the reflection in a puddle and pulls up to reveal the source of the reflection—a glowing neon sign—then continues to pull back to show the rain-soaked streets. Camera Movement: Start focused on a close-up of the puddle's reflection, then pull up and back in one fluid motion to reveal the full context of the rainy cityscape.
An adorable happy otter confidently stands on a surfboard wearing a yellow lifejacket, riding along turquoise tropical waters near lush tropical islands, 3D digital render art style.
A llama sits in a cozy reading nook, surrounded by plush pillows and soft blankets. Warm, golden lighting from a floor lamp creates a welcoming atmosphere. The llama reads a picture book aloud, using expressive voices for the characters. The camera captures the llama's animated face and the illustrations in the book.
A drone camera circles around a beautiful historic church built on a rocky outcropping along the Amalfi Coast, the view showcases historic and magnificent architectural details and tiered pathways and patios, waves are seen crashing against the rocks below as the view overlooks the horizon of the coastal waters and hilly landscapes of the Amalfi Coast Italy, several distant people are seen walking and enjoying vistas on patios of the dramatic ocean views, the warm glow of the afternoon sun creates a magical and romantic feeling to the scene, the view is stunning captured with beautiful photography.
Zero-shot Image to Video Generation
Thanks to the autoregressive nature of our model, our model inherently supports zero-shot (text-conditioned) image-to-video generation. Below, we present the results using unseen (prompt, image) pairs from the internet with a fixed random seed of 0.
a view of a star trail in the night sky
Illustration style of a lightbulb product shot in studio on a background of smaller lightbulbs representing ideas brainstorms.
Hand holding a glowing digital brain, representing the concept of artificial intelligence and innovation in technology.
close up portrait of young bearded guy with long beard.
satellite dish pointed at the night sky.
Young woman watching virtual reality in VR glasses in her living room.
Watercolor style of a boy on a paper ship in the blue sea waves.
a close-up of a hippopotamus eating grass in a field
a highland cow with long horns standing in a field
Rocket blasting off from a laptop screen on an organized office table. The rocket leaves the screen and blast into space.
Close up of the feet of a woman in socks walking away on laminate floor at home closeup.
The festive atmosphere highlights the celebration of the new year, showcasing bright lights and shimmering decorations for 2025.
two cars that have been involved in a violent collision
a man holding a tray in front of a brick wall
Text to Short Video Generation Qualitative Comparison
We compare our method with CogVideoX and MovieGen, the two leading competing approaches. Notably, our method is the only one that supports streaming inference with an interactive framerate (9.4FPS). In contrast, the other two methods require at least 210 seconds to generate a ten-second video. Below, we present 5-second video results generated using prompts from MovieGenBench and a fixed random seed of 0.
CogVideoX
MovieGen
CausVid (Ours)
Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
A gorgeously rendered papercraft world of a coral reef, rife with colorful fish and sea creatures.
A Samoyed and a Golden Retriever dog are playfully romping through a futuristic neon city at night. The neon lights emitted from the nearby buildings glistens off of their fur.
Text to Long Video Generation Qualitative Comparison
We compare our method with StreamingT2V and FIFO-Diffusion, the two leading competing methods. Our approach stands out as the only one supporting streaming inference with an interactive framerate (9.4FPS). Below, we present 30-second video results generated using prompts from MovieGenBench and a fixed random seed of 0.
StreamT2V
FIFO-Diffusion
CausVid (Ours)
A drone camera circles around a beautiful historic church built on a rocky outcropping along the Amalfi Coast, the view showcases historic and magnificent architectural details and tiered pathways and patios, waves are seen crashing against the rocks below as the view overlooks the horizon of the coastal waters and hilly landscapes of the Amalfi Coast Italy, several distant people are seen walking and enjoying vistas on patios of the dramatic ocean views, the warm glow of the afternoon sun creates a magical and romantic feeling to the scene, the view is stunning captured with beautiful photography.
An extreme close-up of an gray-haired man with a beard in his 60s, he is deep in thought pondering the history of the universe as he sits at a cafe in Paris, his eyes focus on people offscreen as they walk as he sits mostly motionless, he is dressed in a wool coat suit coat with a button-down shirt , he wears a brown beret and glasses and has a very professorial appearance, and the end he offers a subtle closed-mouth smile as if he found the answer to the mystery of life, the lighting is very cinematic with the golden light and the Parisian streets and city in the background, depth of field, cinematic 35mm film.
Macro shot of a volcano erupting in a coffee cup.
Ablation Studies
Below, we provide visual qualitative comparisons to complement the ablation studies presented in the main paper (Table 4). We compare our method against multiple variants, including Causal Teacher (50 steps), Ours w/ Causal Teacher (4 steps), and Ours w/ Bidrectional Teacher (4 steps). The Ours w/ Bidirectional teacher is our final configuration. We prsent 10-second 12 FPS video results generated using prompts from MovieGenBench and a fixed random seed of 0. These comparisons demonstrate that the distillation from a bidirectional teacher model, as employed in our approach, is crucial for generating high-quality videos.
Causal Teacher (50 step)
Ours w/ Causal Teacher (4-step)
Ours w/ Bidrectional Teacher (4-step)
Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
Comparison with Bidirectional Teacher Model
As demonstrated by the quantitative and human evaluations in the paper, our distilled causal model surpasses the bidirectional diffusion teacher in frame-wise quality. However, it demonstrates minor shortcomings, including slightly increased temporal flickering and reduced diversity, pointing to areas for further improvement. Below, we prsent 10-second 12 FPS video results generated using prompts from MovieGenBench.
Bidrectional Teacher (50 step)
Ours (4-step)
The slow melting of a snowman, with water trickling down its sides and puddles forming around its base as the temperature warms.
A dynamic motion shot of a paper airplane morphing into a swan. The pointed nose becomes a graceful neck and head, wings unfolding and expanding. The camera moves around as the flat surfaces gain volume, creases softening into feathers. The tail section splits into webbed feet. The transformation finishes as the swan's plumage turns pristine white, its beak forming from the paper's final fold.
Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
Cinematic closeup and detailed portrait of a reindeer in a snowy forest at sunset. The lighting is cinematic and gorgeous and soft and sun-kissed, with golden backlight and dreamy bokeh and lens flares. The color grade is cinematic and magical.
a spooky haunted mansion, with friendly jack o lanterns and ghost characters welcoming trick or treaters to the entrance, tilt shift photography.
A drone camera circles around a beautiful historic church built on a rocky outcropping along the Amalfi Coast, the view showcases historic and magnificent architectural details and tiered pathways and patios, waves are seen crashing against the rocks below as the view overlooks the horizon of the coastal waters and hilly landscapes of the Amalfi Coast Italy, several distant people are seen walking and enjoying vistas on patios of the dramatic ocean views, the warm glow of the afternoon sun creates a magical and romantic feeling to the scene, the view is stunning captured with beautiful photography.
Macro cinematography, slow motion shot: A sculptor's hands shape wet clay on a wheel, and as the wheel spins. Camera captures the tactile quality of the clay and the fluid motion of the sculptor’s hands.
BibTeX
@inproceedings{yin2025causvid,
title={From Slow Bidirectional to Fast Autoregressive Video Diffusion Models},
author={Yin, Tianwei and Zhang, Qiang and Zhang, Richard and Freeman, William T and Durand, Fredo and Shechtman, Eli and Huang, Xun},
journal={CVPR},
year={2025}
}